【Moontalk市場觀察】光通訊產業深度研究:從 GPU 瓶頸到 Optical Networking 的投資邏輯(上)
從GPU瓶頸到互連革命,解析Scale-up崛起、CPO變革與光網路TAM爆發的核心邏輯


摘要:
不少投資人都已經注意到,光通訊產業相關股票的明顯上漲。隨著AI基礎設施持續演進,下一個競爭焦點正轉向「網路(Networking)」,核心在於透過高速且低延遲的資料傳輸來放大整體運算效能。儘管市場對不同網路架構之間是否存在替代關係有所疑慮,但更可能的情況是,各類架構將同時擴張、共同成長。
從技術演進來看,當系統由GB300 NVL72升級至Rubin Ultra NVL576(從單一機櫃72顆GPU擴展至跨機櫃整合),每單位算力所對應的網路價值顯著提高。其中,Scale-out與Scale-up架構的網路價值分別可放大約16倍與45倍,並進一步推動可插拔光模組、CPO(共封裝光學)光引擎、銅纜以及PCB中板等相關零組件需求同步成長。
在市場規模方面,以每單位算力計算,機構預期光模組與光引擎的可服務市場(TAM)將擴大約13倍。僅就Scale-out架構而言,可插拔光模組的價值也提升約10倍;即使假設CPO滲透率達到29%,模組數量仍會由216顆大幅增加至約2,500顆。
今天Moon想進一步針對光通訊產業,進行更深入的細節分析。
一、光通訊是什麼?為什麼 AI 時代一定需要它?
1. 光通訊的定義與底層邏輯
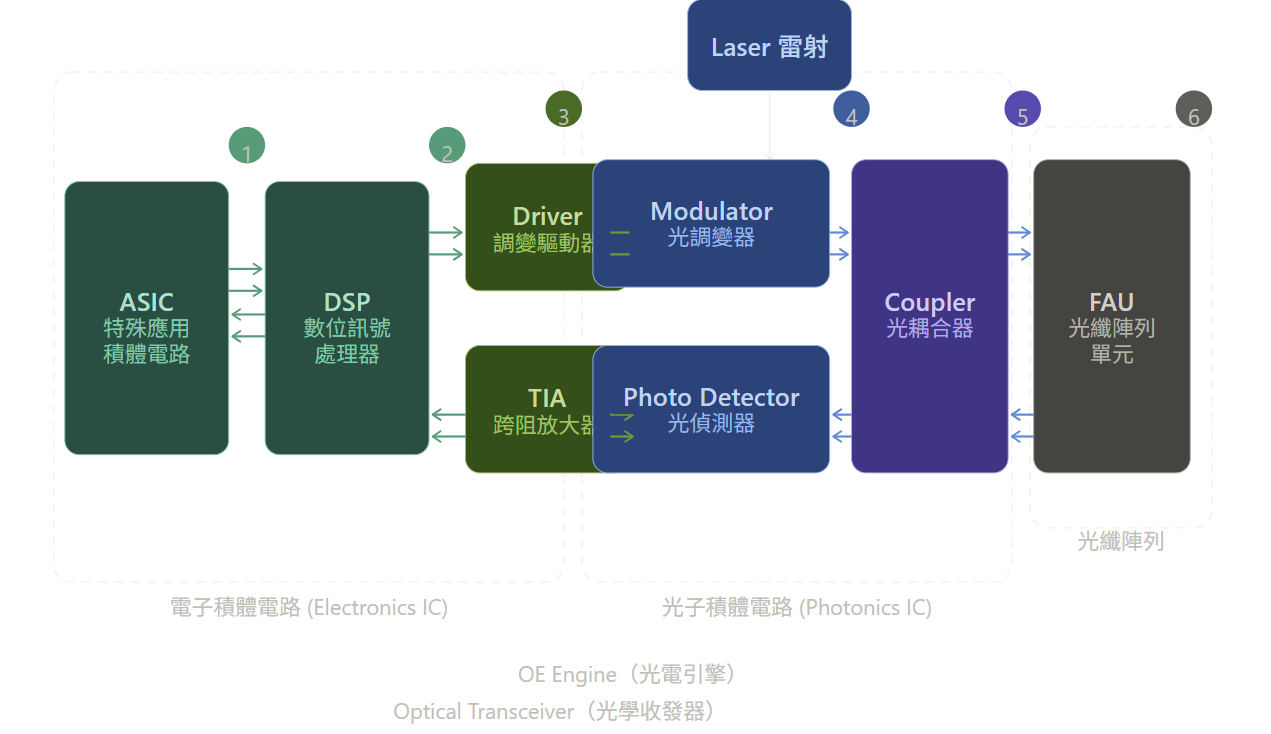
光通訊(Optical Communication)是指利用光波作為載波,光纖作為傳輸介質,進行資訊傳遞的技術。在資料中心內部,伺服器與交換機之間產生的是電子訊號,光通訊系統透過「光收發模組(Optical Transceiver)」將電子訊號轉換為光訊號(電轉光,E/O),經由光纖傳輸至目的地後,再將光訊號轉換回電子訊號(光轉電,O/E)供處理器運算。
中文圖視:
英文圖視:
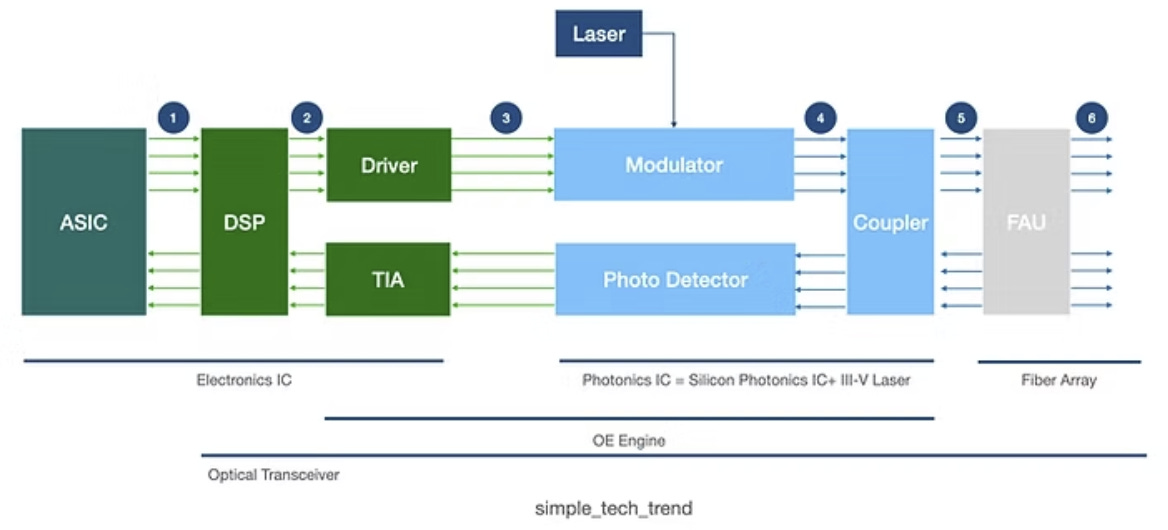
Source: Simple Tech Trend
在開始介紹其他部分前,先簡單介紹關鍵詞,以下是各元件的說明:
電子積體電路(Electronics IC)區塊
ASIC(特殊應用積體電路):專為特定任務設計的晶片,負責高速資料的編碼、解碼與協定處理,是整個收發器的「大腦」。
DSP(數位訊號處理器):對數位訊號進行均衡、補償與糾錯,確保訊號品質,尤其在長距離傳輸後能有效修復失真。
Driver(調變驅動器):接收 DSP 的數位訊號後,將其放大轉換為適合驅動光調變器的電氣訊號(發射路徑)。
TIA(跨阻放大器,Transimpedance Amplifier):將光偵測器輸出的微弱電流訊號放大轉換為電壓訊號,供 DSP 處理(接收路徑)。
光子積體電路(Photonics IC)區塊
Laser(雷射光源):產生穩定的連續波光訊號,作為資訊載體;通常使用 III-V 族半導體雷射(如 InP)整合於矽光子晶片上。
Modulator(光調變器):根據驅動器輸入的電訊號,快速調整光的強度或相位,將電信號「寫入」光波(發射)。
Photo Detector(光偵測器):將接收到的光訊號轉換回電流訊號,是光→電轉換的核心元件(接收)。
Coupler(光耦合器):分配或合併光訊號,將發射光與接收光導引至正確路徑,並連接晶片與外部光纖。
光纖陣列(Fiber Array)
FAU(光纖陣列單元,Fiber Array Unit):將多根光纖精密排列並對準晶片的光學端口,負責晶片與外部光纖網路之間的物理光學連接。
整體路徑可簡單理解為:
電訊號 → ASIC/DSP 處理 → Driver 驅動 → Modulator 調變成光 → Coupler 導引 → FAU 送入光纖,反向則由 FAU 接收光 → Coupler → Photo Detector 轉電 → TIA 放大 → DSP 解調
2. 為什麼資料中心從 Copper 走向 Optical?
傳統資料中心內部大量依賴銅線(Copper)進行短距離連接。然而,在 AI 訓練(Training)與推論(Inference)的過程中,資料搬運的規模呈現指數級增長。銅線在傳輸高速訊號時,面臨著無法克服的物理極限:趨膚效應(Skin Effect)與介電損耗(Dielectric Loss)。當傳輸速率提升至 100Gbps 甚至 200Gbps 每通道(Per Lane)時,銅線的有效傳輸距離急遽縮短至 1 到 2 公尺以內,且訊號衰減極為嚴重,需要消耗大量電力進行訊號補償。

3. GPU Cluster 的高度依賴與「互連瓶頸」
在分散式機器學習中,模型參數與梯度需要在成千上萬顆 GPU 之間進行同步。這導致 GPU 叢集內部產生了海量的東西向流量。
我們可以引入一個核心比喻:GPU 是引擎,而 Optical Networking 是高速公路。如果高速公路的車道不夠寬(頻寬不足)或速限太低(延遲過高),再強大的引擎也無法發揮全速。在實際的 AI 訓練任務中,GPU 常常處於「不是在運算,而是在等待資料(Data Starvation)」的狀態。因此,真正的 Bottleneck 不是 Compute,而是 Interconnect。
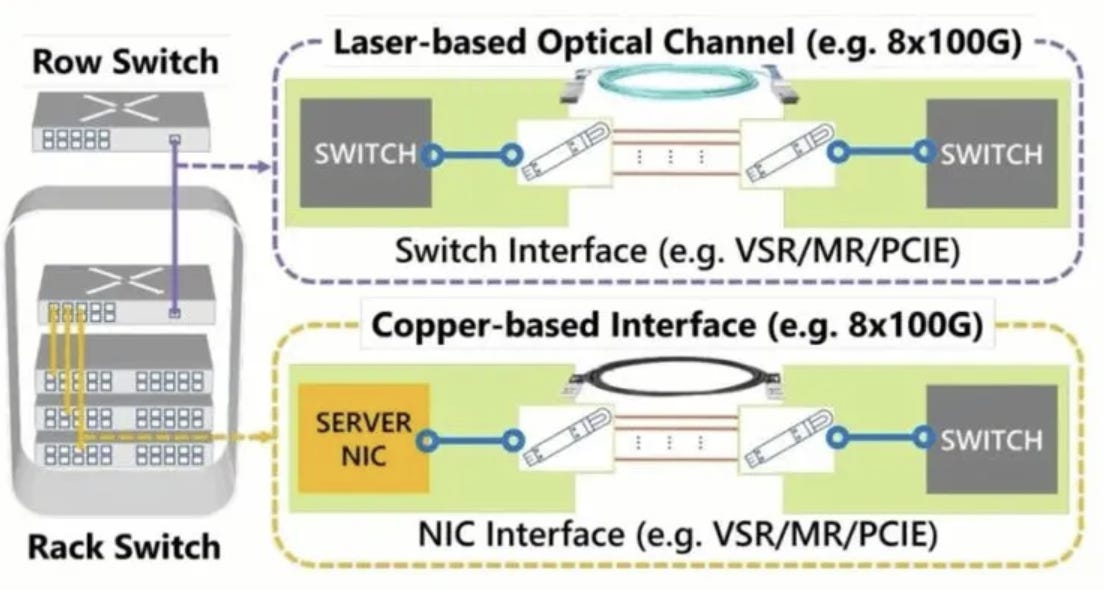
Source: Vocus
4. 光通訊的三大絕對優勢
在 AI 時代,光通訊之所以成為必然選擇,源於其具備三大物理優勢:
更高頻寬(Higher Bandwidth): 光波的頻率極高,可透過波分復用(WDM)技術在單根光纖中同時傳輸多路訊號,輕鬆實現 800G 甚至 1.6T、3.2T 的傳輸速率。
更長距離(Longer Reach): 光訊號在石英光纖中的衰減極低,可輕易跨越數十公尺至數十公里的距離,完美解決大型 GPU 叢集跨機櫃、跨資料中心的連接需求。
更佳功耗效率(Better Power Efficiency at Distance): 雖然光電轉換本身需要耗電,但在中長距離的高速傳輸下,光通訊的每位元功耗(pJ/bit)遠低於需要重度訊號放大的銅線傳輸。
二、談討GW與 AI Data Center 的真正限制
1. GW 的定義與市場關注焦點
GW(Gigawatt,十億瓦或吉瓦)是衡量電力容量的單位。在傳統雲端運算時代,資料中心的電力容量通常以 MW(Megawatt,百萬瓦)為單位計算。然而,隨著 AI 基礎設施的爆發,市場與科技巨頭(如 Microsoft、Google、Amazon)在討論新建資料中心時,已全面轉向以 GW 為單位的規劃。一個 1 GW 的資料中心,其耗電量相當於一座中型城市的總用電量。
2. 電力成為 Scaling 上限
AI 資料中心的功耗之所以如此驚人,不僅僅是因為 GPU 本身(如 NVIDIA H100 功耗達 700W,B200 甚至超過 1000W),Networking(網路互連)同樣是耗電巨獸。
這裡存在一個嚴密的邏輯鏈:為了提升 AI 叢集的算力,必須增加 GPU 數量並提升互連頻寬(頻寬 ↑);在現有技術架構下,推動更高頻率的電子訊號與光電轉換需要消耗更多的能量(功耗 ↑);當單一機櫃的功耗從傳統的 10-15kW 飆升至 AI 機櫃的 100-120kW 時,整個資料中心的總電力需求便呈現指數級上升(GW ↑)。
最終,電力供應與散熱能力,成為了 AI 算力擴展(Scaling)的絕對物理上限。
3. 光通訊作為解決功耗危機的關鍵路徑
在電力受限的框架下,降低每位元資料傳輸的功耗(Energy per bit)成為產業的生死存亡之戰。光通訊技術的演進(如採用更先進的 DSP 製程、矽光子技術、以及未來的 CPO 架構),其核心目標之一便是大幅降低互連功耗。若無法透過光通訊技術的革新來壓低 Networking 的功耗佔比,AI 資料中心將無法在有限的 GW 容量內部署更多的 GPU,這直接凸顯了光通訊在 AI 基礎設施中的戰略地位。
三、Scale-out vs Scale-up
要真正理解光通訊市場的總可潛在市場(TAM)為何會出現爆炸性增長,必須引入兩個概念:Scale-out(橫向擴展)與 Scale-up(縱向擴展)。
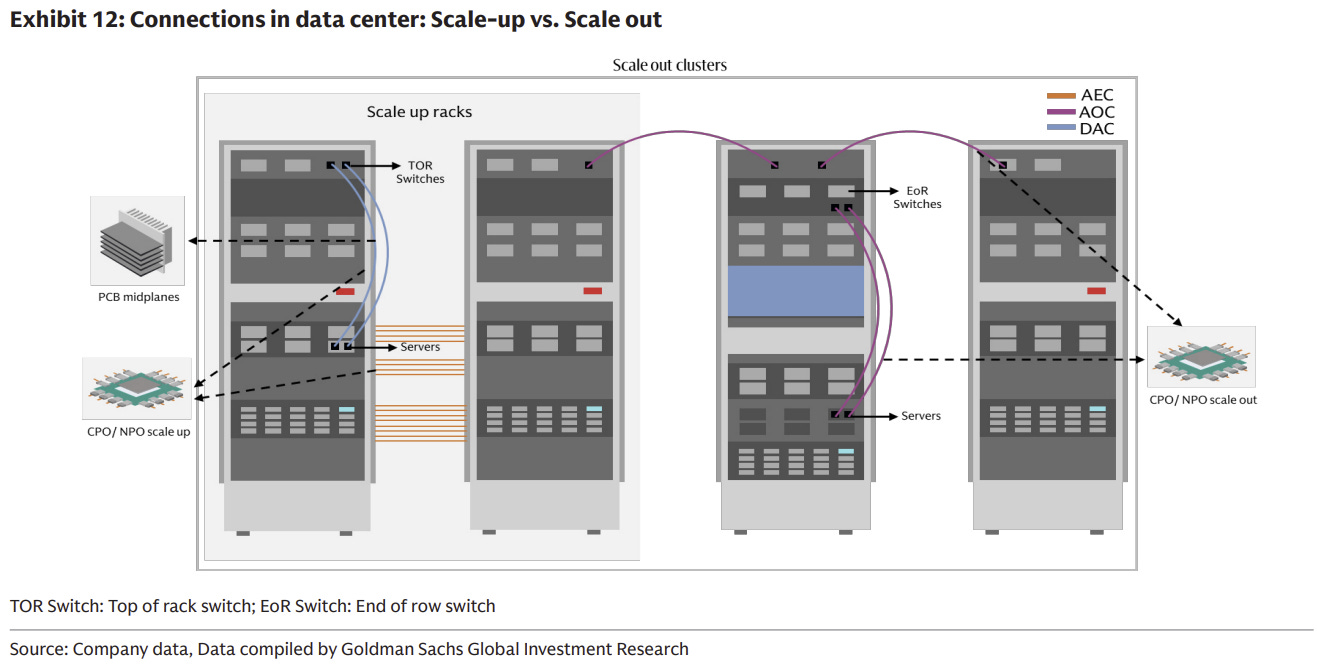
Source: Goldman Sachs Research
1. Scale-out(橫向擴展):傳統的網路互連
Scale-out 指的是透過增加更多的伺服器節點與機櫃,來擴大整個叢集的規模。在 AI 架構中,這通常依賴 InfiniBand 或 Ethernet 網路進行節點間的連接。在 Scale-out 架構中,光模組、光纖與 Switch 扮演著核心角色。過去幾年,市場對光通訊的認知與估值模型,主要建立在 Scale-out 帶動的 800G 光模組需求上。
2. Scale-up(縱向擴展):光通訊滲透的新藍海
Scale-up 指的是在單一系統(或邏輯節點)內,增加更多的 GPU 並讓它們共享記憶體,使其運作起來如同「一顆巨大的 GPU」。NVIDIA 的 NVLink 技術便是 Scale-up 的核心。從 NVL72 到未來的 NVL144,甚至更大規模的 Supernode,單一系統內的 GPU 數量正在急遽增加。
過去,Scale-up 內部的連接(如同一個機櫃內的 GPU 互連)距離極短,主要依賴銅線(Copper DAC)。但隨著 Scale-up 系統規模的擴大,跨機櫃的 NVLink 連接距離超過了銅線的物理極限,光通訊開始強勢滲透進 Scale-up 領域。
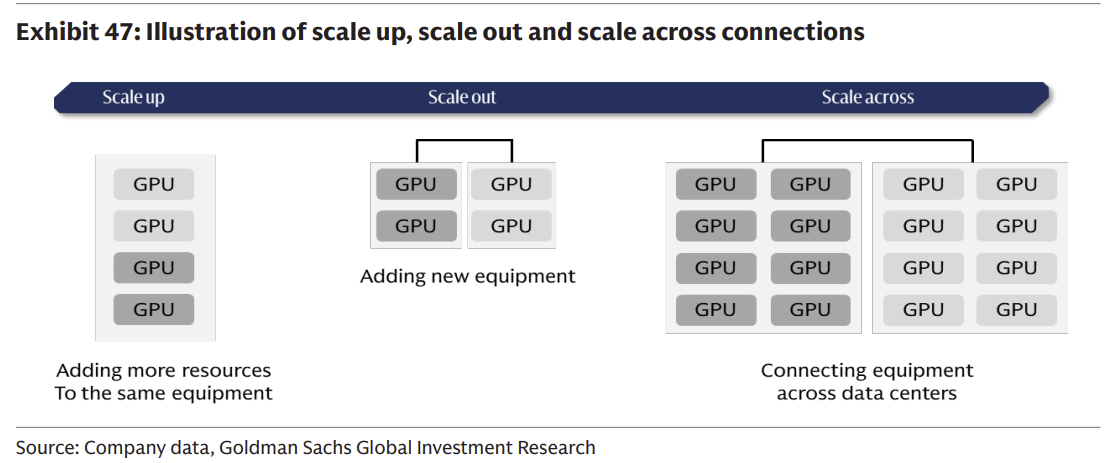
Source: Goldman Sachs Research
3. TAM 爆炸的真正原因與關鍵數據
市場過去只關注 Scale-out,但真正的價值重估正在發生於 Scale-up。根據機構數據,這一技術演進帶來了驚人的市場增量:
TAM 的躍升: 整個互連市場的 TAM 將從 GB300 世代的約 US$15bn,暴增至未來 Rubin Ultra 世代的 US$154bn。
Dollar Content(單機價值量)的非線性增長: 在此演進過程中,Scale-out 的 dollar content 增加了約 16 倍;而 Scale-up 的 dollar content 則呈現了驚人的 45 倍增長。
結構性反轉: 預計到 2028 年,高達 69% 的 TAM 將來自 Scale-up,徹底顛覆過去以 Scale-out 為主的市場結構。
這意味著,光通訊的應用場景正在從「資料中心的骨幹網路」下沉至「運算節點的內部神經」,這種滲透率的提升是光通訊產業鏈迎來戴維斯雙擊(Davis Double Play)的底層邏輯。
四、三種主要連接技術(PCB / Copper / Optics)
在探討光通訊的絕對優勢前,需要先評估資料中心內部的三種主要連接技術,理解其各自的邊界與適用場景:
在 AI 資料中心中,不同連接技術會依據「距離與速度」進行分工:短距離連接主要依賴銅纜(Copper)與 PCB,因其具備成本低與功耗低的優勢;而在長距離或高速傳輸場景中,則以光纖(Optics)為主,因其擁有更佳的訊號品質與更高的頻寬。由於銅在長距離或高速傳輸下容易出現訊號衰減問題,使其性能快速下降,因此隨著資料中心對頻寬與規模的需求提升,光連接的重要性也隨之大幅提高。
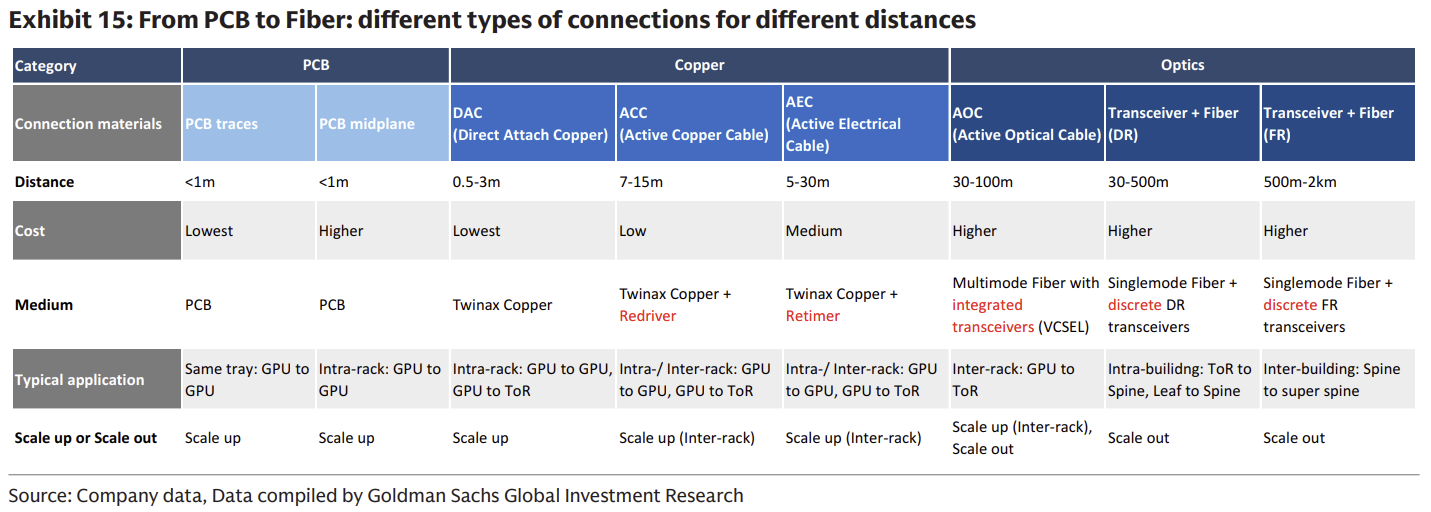
Source: Goldman Sachs Research
PCB(Printed Circuit Board,印刷電路板)
PCB 是伺服器內部最基礎的連接介質,可視為所有晶片之間的「底層通道」。其銅箔走線主要用於極短距離(板內 / tray 內)的訊號傳輸,通常在數十公分以內,具備最低成本、最低功耗與最高整合密度的優勢。然而,隨著 PCIe 5.0/6.0 與 112G/224G SerDes 等高速訊號普及,高頻訊號在 PCB 上的損耗快速上升,不僅需要採用昂貴的超低損耗材料(Ultra-Low Loss CCL),傳輸距離也受到嚴格限制。因此,PCB 雖然是不可或缺的基礎,但其應用範圍主要侷限於最短距離、高密度的連接場景(如晶片內與板內)。
Copper(銅連接:DAC / AEC)
銅連接主要用於短至中距離(機櫃內,甚至鄰近機櫃)的傳輸,是 PCB 與光通訊之間的過渡方案。DAC(Direct Attach Cable)適用於極短距離(通常 <3 公尺),具備低成本、低功耗且無需光電轉換的優勢,因此在現有架構(如 NVL72)中仍被廣泛採用。為延伸距離,AEC(Active Electrical Cable)透過內建 retimer 可將距離提升至約 5–30 公尺,但代價是功耗與成本上升。整體而言,銅連接在距離與成本之間取得平衡,但其物理限制(訊號衰減、體積與重量)在高速(如 200G/lane)下迅速惡化,使其難以支撐更大規模與更高頻寬的系統。
Optics(光通訊)
光通訊主要用於中長距離至長距離(跨機櫃 / 資料中心)的高頻寬傳輸,是大規模 AI cluster 的關鍵基礎設施。雖然光模組需要光電轉換,帶來較高的成本與一定功耗,但在高速與長距離條件下,其訊號完整性、頻寬擴展能力與能效表現遠優於銅連接。因此,光通訊幾乎主導所有 scale-out(機櫃之間)場景,且隨著頻寬需求提升,正逐步從傳統可插拔模組延伸至 NPO(板上光學)與 CPO(共封裝光學),開始滲透至部分 scale-up(機櫃內)應用。
綜合上述比較,可以看出三種連接技術是依據「距離 × 頻寬 × 成本」形成清晰分工:PCB 作為板內與超短距離的基礎連接,提供最高密度與最低功耗;銅連接在機櫃內扮演成本與性能的折衷方案;而光通訊則在中長距離與超高頻寬需求下成為不可替代的核心技術。
隨著 AI 系統持續向更大規模與更高頻寬演進,光技術逐步從機櫃間滲透至機櫃內,銅連接的應用範圍被壓縮至更短距離,而 PCB 則持續透過材料升級與 midplane 設計支撐高密度整合。這種分層且動態演進的架構,正是推動 AI 資料中心網路價值(dollar content)持續提升的核心原因。
五、完整的光通訊產業鏈
1. 上游:核心元件與晶片 - 高技術壁壘、高毛利
(1) Laser(雷射晶片)
雷射是光通訊的「光源引擎」。主要分為連續波雷射(CW Laser,主要用於矽光子架構)與電吸收調變雷射(EML,目前高速光模組的主流)。雷射晶片的製造涉及複雜的化合物半導體(如 InP 磷化銦)製程,良率控制極難。全球具備高階 EML 量產能力的廠商極少,呈現寡占格局。其投資特性為資本密集、技術迭代慢但壁壘極高。
(2) SiPh(Silicon Photonics,矽光子)
矽光子技術是將光學元件(如調變器、探測器)整合到傳統的矽基半導體晶片上。矽光子的本質,是讓光通訊產業走向類似早期半導體產業的標準化與規模化。它能大幅降低光模組的封裝複雜度與成本。長期來看,矽光子是通往 CPO(共封裝光學)的必經之路,具備極高的長期投資戰略價值。
(3) 高速晶片(DSP / SerDes / Switch ASIC)—— 上游產業鏈的定價權核心
DSP(數位訊號處理器): 在 400G/800G 時代,訊號調變技術從簡單的 NRZ 轉向複雜的 PAM4(四階脈衝振幅調變)。PAM4 雖然提升了頻寬,但極易產生雜訊與誤碼。DSP 的作用就是透過強大的算力進行前向錯誤更正(FEC)與訊號補償。
SerDes(串列解串器): 負責將平行的低速訊號轉換為串列的高速訊號,是晶片對外溝通的咽喉。
Switch ASIC(交換器特殊應用晶片): 網路設備的大腦,決定了資料轉發的總頻寬。
2. 中游:光模組與光引擎
(1) 光模組(Optical Module / Transceiver)
光模組負責電和光的核心轉換。在 800G 與即將到來的 1.6T 時代,光模組是目前整個產業鏈中業績兌現最快的環節。核心壁壘在於:
高階產品的良率控制: 800G/1.6T 模組內部光路極其複雜,微米級的對位偏差都會導致產品報廢。
客戶認證壁壘: 雲端巨頭(如 Google、Meta)與 NVIDIA 對光模組的可靠性要求極高,認證週期長達數月至一年,一旦進入供應鏈便難以被替換。
根據機構數據,隨著架構演進,光模組與 GPU 的 Attach Rate(配比率)從過去的 1:2–3 飆升至 1:4–6;單一叢集的光模組數量(Units)從 216 顆暴增至 2,500+ 顆;同時,高階模組的 ASP(平均售價)從 US$800 翻倍至 US$1,600。市場過去常常忽略「每顆 GPU 背後的 Optical Content 正在非線性上升」這一事實,這正是頭部光模組廠商 EPS 呈現爆發性增長的核心邏輯。
(2) 光引擎(Optical Engine)
光引擎是光模組內部的核心次系統,通常包含雷射、調變器與探測器,但不包含 DSP 與外部金屬外殼。在未來的 CPO 架構中,光引擎將被獨立出來,直接與 Switch ASIC 或 GPU 封裝在一起。掌握光引擎設計與先進封裝能力的廠商,將在下一代技術變革中佔據先機。
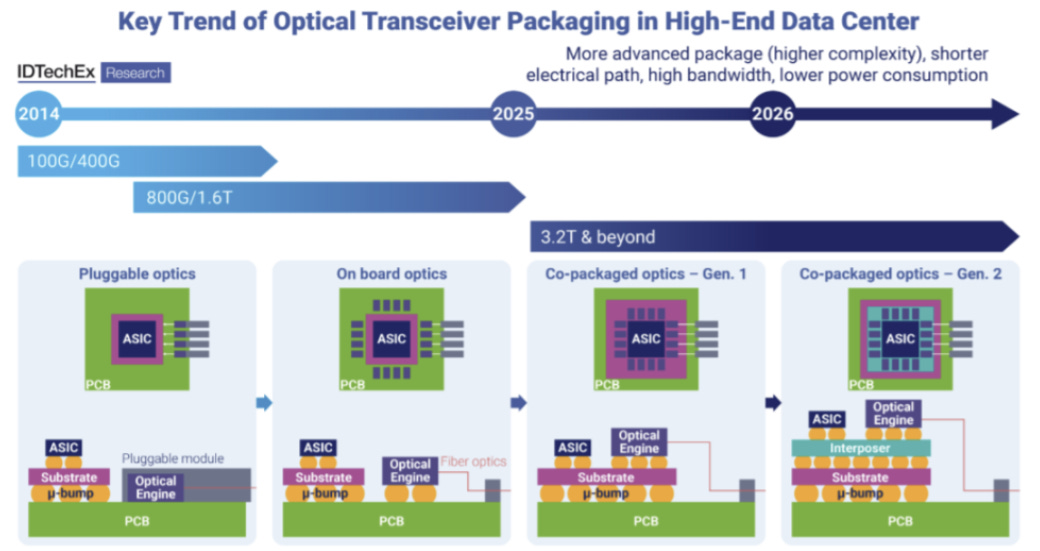
3. 下游:系統設備
包含 Switch(交換器)、Router(路由器)與 Server(伺服器)。核心角色是將光模組插入設備端口,形成完整的網路基礎設施,本質是實現「算力之間的物理連接」。
系統設備商(如 Cisco、Arista、NVIDIA Networking)的商業模式是「吃量但不是最賺」。他們的毛利率容易受到上游強勢晶片商(如 Broadcom)的擠壓。然而,只要全球雲端服務供應商(CSP)的 AI 資本支出維持強勁,系統設備的需求就具備高度的穩定性與可預測性。
六、Pluggable vs CPO - 產業的最大技術變革
光通訊產業目前正處於一個關鍵的技術十字路口:從傳統的可插拔光模組(Pluggable)向共封裝光學(CPO, Co-Packaged Optics)演進。這是理解未來五年產業競爭格局的最重要變數。
1. 傳統 Pluggable 架構與其面臨的瓶頸
在傳統架構中,資料流向為:GPU/Switch ASIC → PCB 銅線走線 → 面板上的可插拔光模組 → 光纖。這種架構的優點是維護方便,但面臨嚴峻挑戰:
長距離電傳輸損耗: 晶片到面板光模組之間有數十公分的 PCB 距離,在 224G 速率下,這段「電傳輸」會產生巨大的訊號衰減。
功耗與發熱極高: 為了克服上述衰減,必須在光模組內使用高功耗的 DSP 進行訊號補償,導致面板區域熱密度極高,散熱成為災難。
2. 未來 CPO 架構:重構價值鏈
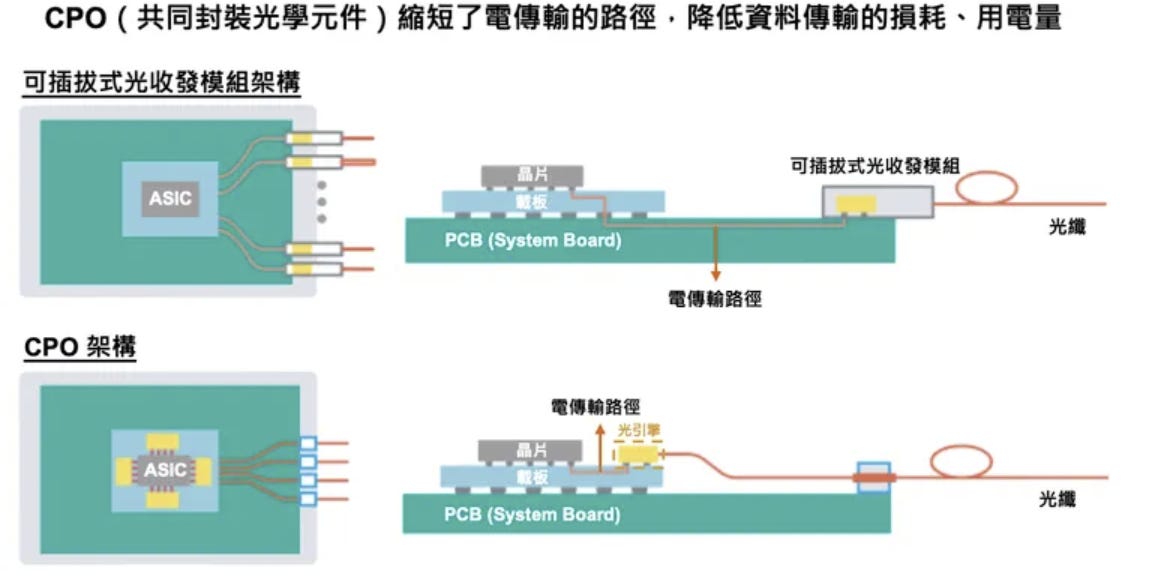
Source: Vocus
CPO(Co-Packaged Optics)的核心理念是將光引擎(Optical Engine)從面板移到晶片旁邊,與 Switch ASIC 或 GPU 封裝在同一個基板(Substrate)上。資料流向變為:GPU/ASIC → 極短距離基板走線 → 光引擎 → 光纖。
優勢: 徹底消除了 PCB 上的長距離電傳輸,大幅降低了對 DSP 的依賴,從而顯著降低系統總功耗與延遲。
價值鏈改變: CPO 將顛覆現有的利益分配。傳統光模組的外殼與部分 DSP 價值被消滅;掌握先進封裝技術的晶片廠(如 Broadcom)與具備光引擎製造能力的廠商將成為最大贏家。
機構預期速度升級將持續至 2028 年,從 800G 在 2026 年提升至 1.6T,並在隨後幾年邁向 3.2T 及以上,同時中國雲端廠商的速度升級將跟進,進而延長整體升級週期。為了滿足日益增加的頻寬需求、功耗壓力以及小型化需求,光連接的形式正在演進:
(1)可插拔光模組正從 EML 轉向矽光(Silicon Photonics),其具備更高整合度、更低成本以及對雷射供應依賴降低的優勢
(2)連接形式由可插拔光模組進一步擴展至板上光學(NPO)與共封裝光學(CPO),以支援短距離高頻寬連接並提升能效。
CPO 初期將與交換晶片(switch ASIC)整合,之後再擴展至各類 XPU(如 GPU、CPU、ASIC 等)。
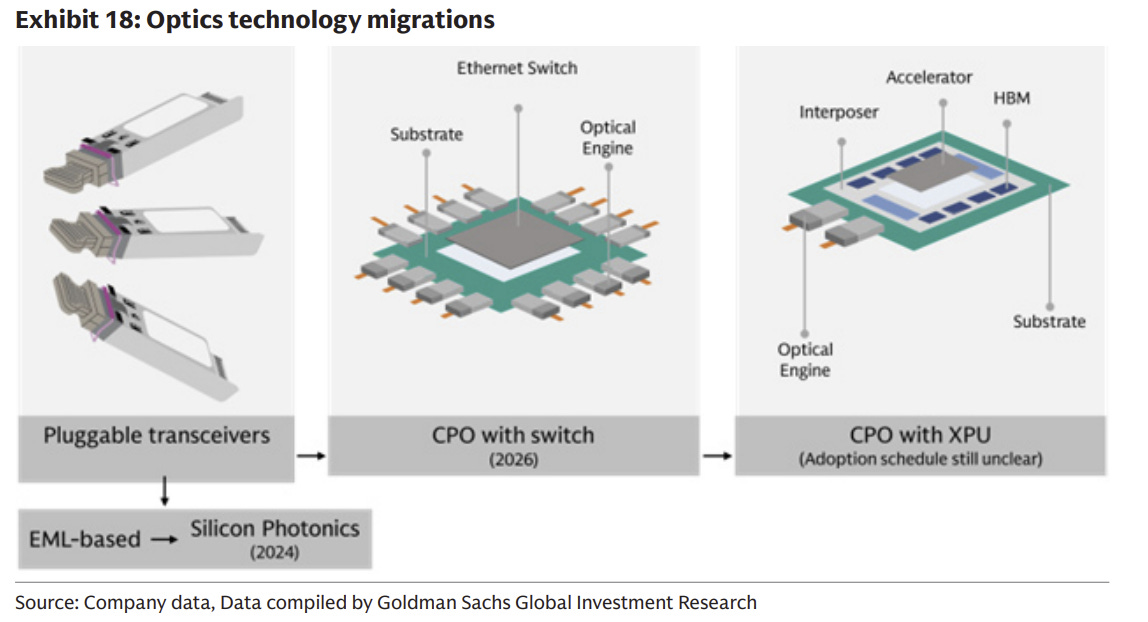
3. 破除迷思:Pluggable 與 CPO 將長期共存
市場常有一種誤解,認為 CPO 會迅速且全面地取代 Pluggable。從機構投資視角來看,這是不準確的。CPO 面臨著極高的技術挑戰(如雷射光源的散熱與可靠性問題、封裝良率問題、以及商業模式上誰來承擔保固責任)。
因此,Pluggable 不會被完全取代,而是會與 CPO 長期共存。在超大規模的 Scale-up 核心節點或對功耗極度敏感的 Switch 核心,CPO 將佔據主導;而在跨資料中心連接或邊緣網路,Pluggable 仍將是主流。
七、投資框架
1. 利潤分配 :誰吃最多利潤?
在光通訊產業鏈中,利潤率與定價權呈現明顯的階層分佈:
高速晶片(DSP / Switch ASIC): Broadcom 與 Marvell 憑藉極高的技術壁壘與寡占格局,享有最強的定價權與最高的毛利率(通常在 60%-70% 以上)。
高階光模組(800G / 1.6T): 階段性利潤收割者。在技術迭代初期(如目前的 800G 週期),頭部廠商憑藉良率優勢與產能稀缺性,享有極高的超額利潤。
光引擎 / SiPh: 未來的利潤增長極高。目前處於技術投入期,但隨著 CPO 時代到來,其價值佔比將大幅提升。
網通設備(Switch / Router): 穩定獲利者。毛利率受制於上游晶片,但營收規模龐大,賺取的是系統整合與軟體服務的利潤。
傳統光元件: 利潤最薄弱。競爭激烈,產品同質化高,主要依靠規模效應壓低成本。
2. 最大受益者與公司定位
在該產業研究的第二篇,Moon將會研究全球主要光通訊相關標的。
八、結論
在 AI 基礎設施的投資浪潮中,市場的定價邏輯正在發生深刻的演變。過去兩年,資本市場已經對 GPU 與 Compute(算力)進行了極其充分的定價,NVIDIA 的市值奇蹟便是最佳註解。
然而,隨著 AI 模型參數的無極限擴張,以及資料中心面臨嚴峻的 GW 級電力限制,解決「資料搬運效率」與「互連功耗」已成為 AI 產業能否持續 Scaling 的關鍵。光通訊技術,憑藉其在頻寬、距離與功耗上的絕對物理優勢,正以前所未有的速度從資料中心的骨幹網路,深度滲透至 GPU 運算叢集的核心。
深刻理解光通訊的技術演進與價值鏈重構,並在 DSP 寡占巨頭、高階光模組龍頭以及具備 CPO 選擇權價值的核心元件商中進行結構性佈局,將是捕捉 AI 基礎設施下半場Alpha的關鍵路徑。
Source: Simple Tech Trend, Vocus, 九方智投, Goldman Sachs Research
本文不構成投資建議。所有分析均為個人研究觀點,投資決策需結合個人風險偏好與最新市場數據進行獨立判斷。
太佛了❤️
這是我看過講解最詳細的報告,謝謝您!